五大趋势引领,数据密集化成新一代超算关键特征
重视数据,实现以数据为中心,牵引采、存、算、传、用多维度均衡发展的数据密集型超算,将是中国的超算强国之路。
本站点使用cookies,继续浏览表示您同意我们使用cookies。Cookies和隐私政策
超算可谓国之重器,彰显了一个国家的科技发展水平,美日欧俄等发达国家均高度重视超级计算机系统的研制与发展,世界各国激烈竞争,纷纷进行战略顶层设计,以谋求长期的优势地位。经过不懈努力,目前,我国的超级计算机制造技术已走在了世界前列。
在2021年6月发布的世界超级计算机TOP500排名中,中国上榜的超级计算机数量高达188台,稳居世界第一。包括神威太湖之光和天河2号在内的中国超算已连续10次夺得世界第一,成为事实上的超算大国。2020年以来,“十四五”规划及新基建驱动着我国的超算中心建设进入爆发期,国内已有越来越多的省市将建设超算中心及部署新一代超级计算系统作为推动经济社会快速发展的关键措施。目前,我国已拥有10家国家级超级计算中心(天津、深圳、长沙、济南、广州、无锡、郑州、昆山、成都、西安),此外,多地地方政府及企事业单位也在积极建设或筹建超算中心。
近年来,随着云计算、大数据、人工智能、区块链等新兴技术热点层出不穷,社会降低了对于超算技术的关注度。加之国际环境的变化,尤其是美国对中国高科技的打压,也掣肘着核心技术(CPU、GPU、存储器件、高性能互连等)的发展,导致了超算应用的生态受制于人,超算服务仅靠提供机时使得能力模式单一等问题。中国超算呈现出大而不强的特点。
为应对这些问题,中国超算将在算力多样化、网络全光化、数据密集化、应用容器化及架构融合化五方面重点发力,不断牵引超算中心从单一的计算服务提供商转变为综合的数据价值提供商。
首先,多样化算力成为主流。传统的HPC使用CPU进行双精度浮点计算,而新兴的超算系统则使用CPU、GPU及FPGA进行更强大的并行计算。与此同时,加大自主微处理器、加速器的研发力度和部署比例,提升多元化异构算力的算效水平,有效提高多样化混合应用的效率,也成为产业发展的大势所趋。
其次,光交换技术趋于成熟,网络全光化的趋势明显。ROCE及数据无损技术的推出,使得超算中心内部的算力网络、存储网络和管理网络集合成“三网盒子”成为可能。为解决资源的共享问题,超算中心之间的全光超算互联网概念也被提出。
第三,数据的密集化。传统的超算场景如气象预测、能源勘探、卫星遥感等,随着观测尺度的提升,数据量将越来越大;而很多新增的超算场景,如自动驾驶、基因测试及类脑科学,80%以上是PB级的数据密集型场景。更大的数据量、更多的数据类型、更多的并行任务和更高的可靠性要求,都需要超算存储可以提供更大的带宽、更高的IOPS、高可靠性和海量并行的访问能力。
第四,应用的容器化。大部分超算用户并不是专业的计算机用户,采用容器化技术能够提前将超算运行的环境封装好,实现超算应用与底层硬件的解藕,让超算更加易用。此外,由于容器技术目前还处于开源状态,也能有效解决超算面临的生态问题。
第五,超算架构的融合化。为匹配算力多样化、数据密集化、网络全光化及应用容器化的技术趋势,超算将通过异构多态复合的计算架构,促使传统架构中的资源、数据、应用孤岛走向融合。即构建一个统一的异构融合体系,通过统一的业务调度平台,调度CPU、GPU及其他的专用算力;同时,通过统一的应用平台,来管理丰富的超算应用;通过统一的数据基座,来承载数据资产,打破数据孤岛,实现“底座不动、数据不迁”,优化TCO投入,提升投资回报。
五大趋势中数据密集化最为值得关注。传统超算主要解决算的问题,一般情况是客户通过硬盘把数据拷贝到超算中心,计算完成后再从超算中心把数据拷出来,因此,超算中心不需要长期留存数据。随着超算的不断演进,开始出现了一些新的变化与挑战。
首先,参与计算的数据量大幅增长。如气象预报、卫星遥感等应用的精度提升带来了数据量的倍增;同时,参与计算的数据类型更加丰富,除了结构化数据之外,还有非结构化数据,如脑科学、冷冻电镜等场景均需直接使用影像数据进行计算。
第二,算力大幅增加。目前,已很少有单一任务能够消耗完所有的集群算力,因此,大部分场景是多任务并发,如上海交大超算中心的100P算力,并发的任务数接近50个,这些任务中,有的对带宽要求高,有的对IO要求高,这就要求存储具备更加均衡的能力。
第三,对可靠性有更高要求。当传统超算应用于科研项目时,只要能出结果,即使多算几次用户也能接受,但现在的超算更多是应用于生产系统,因此,对结果及过程的可靠性均有更高的要求,这就对存储的可靠性提出了极致要求。
第四,超算中心与数据中心的融合。近年来,超算中心也在探索更多元化的服务,如AI计算、大数据分析、虚拟化、灾备等,这一过程中,数据的流动性成为其面临的最大问题,如超算的文件存储、虚拟化的块存储、机器学习的对象存储、大数据的HDFS存储等均为割裂的状态,如何让数据流动起来,是目前超算中心面临的最大挑战。
这对整个数据存储产业来说,既是挑战,也是机会,驱动超算逐步从计算密集型走向数据密集型。
数据密集型超算是以数据为中心的高性能数据分析平台,具备传统超算、大数据分析及AI的分析能力,其可通过应用驱动统一数据源,支持全流程的科学计算服务,在为科研及商业提供多样性算力的同时,能够基于数据知识的累积,提供高阶的数据价值服务。
数据密集型超算可实现单一计算中心到多元算力中心的过渡,最终通过多元算力融合与海量数据的统一存储底座实现高性能的数据分析,推动超算从算力服务时代走向数据价值时代(图1)。其具有以下几大价值:
其一,科研价值。数据密集型科研发现的HPC+AI+BigData技术融合架构,实现了交叉科学的创新,助力了科学研究从第三范式(计算科学)向第四范式(数据科学)的演进。
其二,商业价值。融合高效、安全低碳,统一数据底座降低了海量结构化\非结构化数据的全生命周期管理成本,提升了科学计算、大数据及人工智能融合应用的使用效率。
其三,产业价值。国产HPDA系统软件、国产并行文件系统、国产数据存储和数据管理系统,推动了国产超算存储产业及应用技术生态的发展。
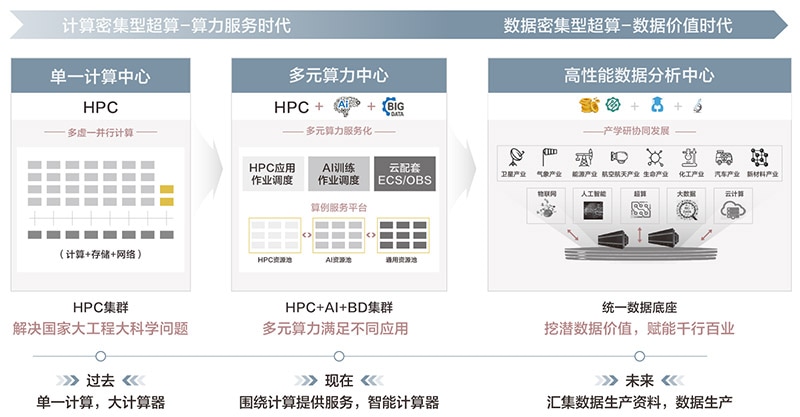
图1 超算进入数据价值时代
当前,数据密集型超算已在科学研究、生产制造及商业活动中获得了广泛应用。
例如,在基因测序中,一台华大智造DNBSEQ-T7测序仪的生产量为:4.5Tb/24h,6Tb/30h。在满负荷状态下,一年就能产生1.7PB左右的数据量,加之生物信息的分析过程,一般会产生原始数据量5倍左右的中间文件及结果。国内著名的华西医院通过引入数据密集型超算,有效提升了基因测序的效率,将单次基因测序的耗时从3个小时优化为分钟级。
在自动驾驶中,其业务非常复杂,不仅包括数据导入、预处理、训练、仿真、结果分析等十多个环节,且各环节要求的协议也各不相同(对象/NAS/HDFS等),数据孤岛的现象严重,数据拷贝时间就达到处理分析时间的2倍以上。吉利-沃尔沃汽车通过引入数据密集型超算,采用一套数据底座,就可支持多协议互通,适配全流程业务,不仅降低了数据的存储成本,也提升了数据分析的效率。
在高校超算中,上海交大的π系列超算及中科大的瀚海系列超算,通过引入数据密集型超算,提供了更为均衡的数据访问能力,可同时支持50多个负载要求不同的超算业务,满足了各种科研计算的需求;同时,在算力更新换代时,无需进行数据迁移,便可长期保存历史数据,有效地支撑了各项科研任务的开展。
此外,国家超算济南中心及长沙中心的数据密集型超算应用示范工程已在规划中,其希望通过承担更多的数据密集型超算业务,在提升客户粘性和忠诚度,解决数据流动和共享问题的同时,通过发掘数据价值,深度参与政企的数字化进程,更好地发挥超算的社会价值和经济价值。
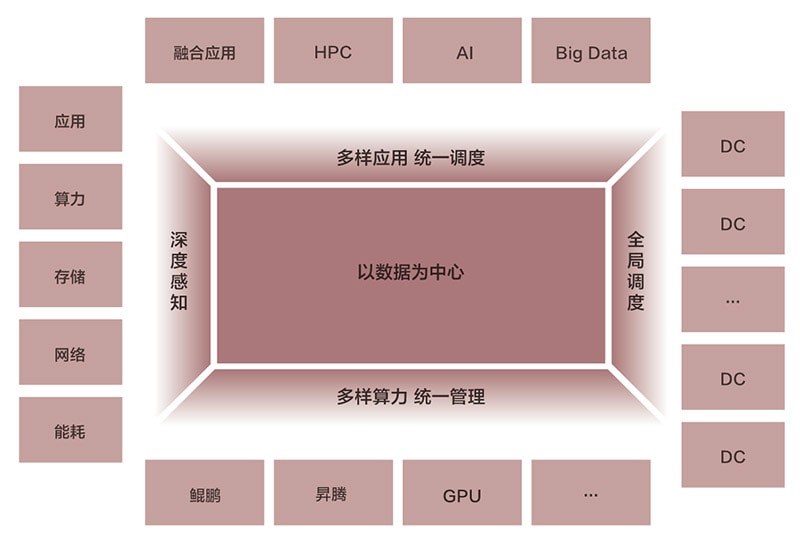
图2 以数据为中心的数据密集型超算
目前,超算产业正积极行动起来,以推动新一代超算的发展。2021年9月底,在兰州举办的第九届超算创新联盟大会上,正式成立了数据密集型超算工作组,将数据上升到与算力同样的高度;10月初,在呼和浩特召开的第七届科学数据大会上,拥有最核心数据资产的20家国家科学数据中心共聚一堂,数据密集型超算成为其热议的话题;在今年召开的HPC China大会上,华为联合CCF高专委正式发布了《数据密集型超算技术白皮书》。
越来越多的产业共识正在凝聚,重视数据,实现以数据为中心,牵引采、存、算、传、用多维度均衡发展的数据密集型超算,将是中国的超算强国之路。

 1
1 2
2 3
3 4
4 5
5 6
6



