东数西算,新型算力网络如何建设?
华为正积极参与国家枢纽节点的方案设计与建设,通过IP网络方案的持续创新,推动“东数西算”工程顺利开展,为数字经济提速注入强劲动力。
本站点使用cookies,继续浏览表示您同意我们使用cookies。Cookies和隐私政策
2021年5月,国家发改委、网信办、工信部、国家能源局四部门联合印发了《全国一体化大数据中心协同创新体系算力枢纽实施方案》(以下简称《实施方案》)。该方案提出,将“构建数据中心、云计算、大数据一体化的新型算力网络体系”,实施“东数西算”示范工程,以实现数据中心的绿色高质量发展。《实施方案》的发布,是对2020年年底发改委发布的《关于加快构建全国一体化大数据中心协同创新体系的指导意见》中一体化大数据中心顶层设计的细化与解读,也是对《中华人民共和国国民经济和社会发展第十四个五年规划和2035年远景目标纲要》中“加快构建全国一体化大数据中心体系,强化算力统筹智能调度”规划的落地与推进。如何构建新型算力网络,已成为我国新型数字基础设施建设的重大课题。
近年来,随着国家数字经济的加速,我国东西部算力设施布局不平衡、不充分的问题愈加凸显。东部地区应用需求大、创新能力强,但土地、水电等配套资源紧张;西部地区气候适宜、能源丰富,但数字产业的层次上还存在较大上升空间。实施“东数西算”工程可有效优化算力与应用的空间布局,有助于形成数据的自由流通、按需配 置、有效共享的全国性要素市场,构建以数据为纽带的东西区域协调发展新格局。
按照《实施方案》的发展规划,我国将在东部的京津冀、长三角、粤港澳大湾区,以及中西部的成渝、贵州、内蒙古、甘肃、宁夏等地布局建设枢纽节点。一方面,枢纽节点将构建数据中心的算力集群,通过数据中心网络联接超大规模计算存储资源,发挥集约化和规模化优势,保证算力的充分供给;另一方面,枢纽节点之间可通过广域网络交换数据与算力,在近端,可满足高频实时交互型业务的需求,在远端,可满足离线分析存储备份等非实时算力的需求。在“东数西算”工程中,网络贯穿了算力的生产、传输和消费的全流程,是构建一体化大数据中心的关键。
将东部的数据在西部进行存储和处理,对网络性能提出了巨大的挑战。在算力供给侧,数据中心存在“1+1远小于2”的业界难题。由于大规模服务器集群依赖于网络实现互联,因此,当多台服务器向一台服务器同时发送大量报文时,会导致报文数量超过交换机的缓存承受能力而产生丢包。而丢包造成的数据重传,又将极大地影响计算和存储的效率。在近些年备受业界青睐的RoCE(RDMA over Converged Ethernet)网络中,0.1%的丢包率就会导致50%的算力下降,造成服务器CPU资源的严重浪费,成为算力提升的瓶颈。
在算力配给侧,广域网络作为联接东部数据与西部算力的跨区域通道,承载着海量企业成百上千的业务,而不同业务对带宽、时延、算力等关键能力存在差异化需求。广域网络必须实现对所承载业务的高效调度,才能让东数西算发挥预期的价值。而传统IP网络提供的尽力而为服务,难以根据不同业务需求进行差异化调度,这种状况不仅导致网络资源、云池资源无法被充分利用,也无法帮助企业选择最优的云池,造成企业上云成本增加及服务体验不佳。
基于近30年网络领域的研发积累与商用实践,华为发布了业界领先的跨区域算力调度IP网络解决方案,其产品构成包括:数据中心CloudEngine 16800系列交换机及NetEngine 8000 F8系列广域路由器。基于智能无损及智能云图两大创新算法,该方案可实现算力生产侧及输送侧的最优调度,从而整体上达到算力损失最小、性能最佳、输送最优。
要解决数据中心网络的丢包问题,关键是要设置合理的交换机缓存队列拥塞标记水线。如果水线设置过高,发端服务器无法及时降速,网络拥塞不能及时缓解,就会出现丢包或时延的大幅增加;如果水线设置过低,发端服务器过度降速,网络无法实现100%吞吐,则会造成资源的浪费。长期以来,由于业务流量模型千差万别,即使网络专家投入大量精力进行测试仿真,依赖人工经验也难以确定最佳水线。为此,华为创新地将智能算法引入数据中心网络交换机,其可根据实时采集的网络状态信息,如队列深度、带宽吞吐、流量模型等维度,通过智能无损算法动态设置最佳的队列水线。为了确保算法可以适应任意场景和流量模型,华为通过百万级的真实业务样本及千万级的随机样本对算法模型进行训练,最终实现了无丢包、高性能、低时延的最佳平衡(图1)。
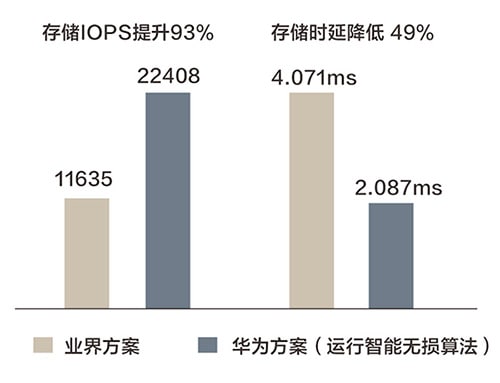
图1 存储网络场景下智能无损算法效果对比(来源Tolly报告)
高性能计算、并行计算需要提供大规模的算力,为了实现海量计算节点的高速互联,要求网络除了零丢包外,还要支持超大规模组网和低时延的诉求。目前,数据中心采用的主流网络架构为CLOS架构(图2),其组网规模会受限于交换机的端口密度。以业界常见的64口交换机为例,3级CLOS架构最大可支持65536个服务器接口,而构建10E级算力需要提供20万以上计算节点的互联能力。此外,3级CLOS网络计算节点间的转发需要经过5跳,而4级CLOS不但组网成本大幅上升,而且跳数也达到7跳,时延增加将导致计算效率明显降低。
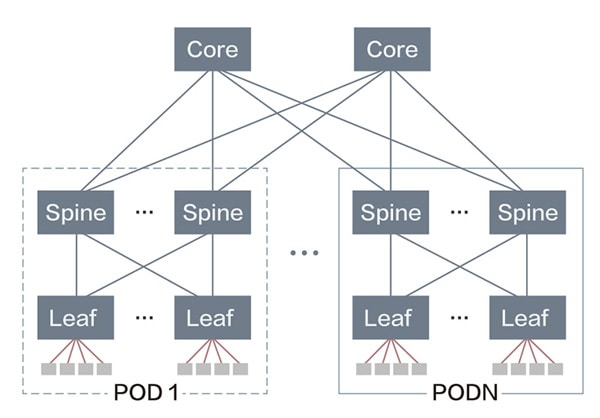
图2 数据中心传统的CLOS组网模式
为了实现更大规模的组网,同时保证低成本及低网络时延,华为将直连拓扑(图3)引入到以太组网中,突破了CLOS架构的限制,实现了超大规模和低网络直径(低跳数)组网。同时,该方案通过创新的分布式自适应路由技术,可充分利用非等价路径实现动态路由,在保证低时延的同时,提高了带宽利用率。华为CloudEngine系列交换机升级后可支持直连拓扑及自适应路由,其中,64口交换机最高可支持27万台服务器的零丢包组网,组网规模达到了业界平均水平(3级CLOS)的4倍,网络跳数和时延可降低25%,在同等服务器组网规模下,相对于3/4级CLOS,网元节点数量可减少20%~40%。
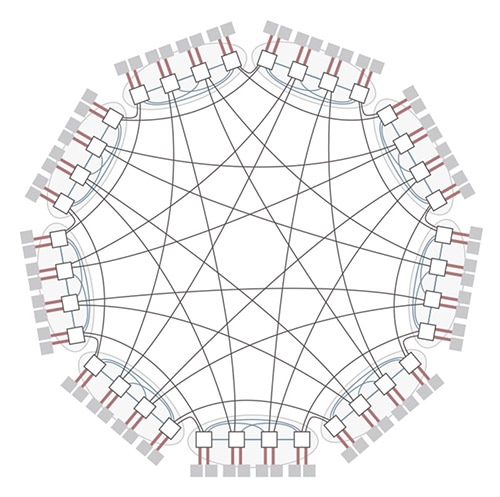
图3 数据中心新型直连拓扑组网
传统广域网采用的最短路径调度,会由于业务选择相同路径而造成链路利用率不均衡。引入多路负载分担后,虽然提升了网络的利用率,但业务对网络的差异化需求(如时延、抖动、可靠性)并未得到满足。同时,这种方式仅考虑了网络因素,而未考虑云池因素(如算力负载、成本、存储),因此,会造成云端算力资源利用不均衡,无法实现算力的高效调度(图4)。
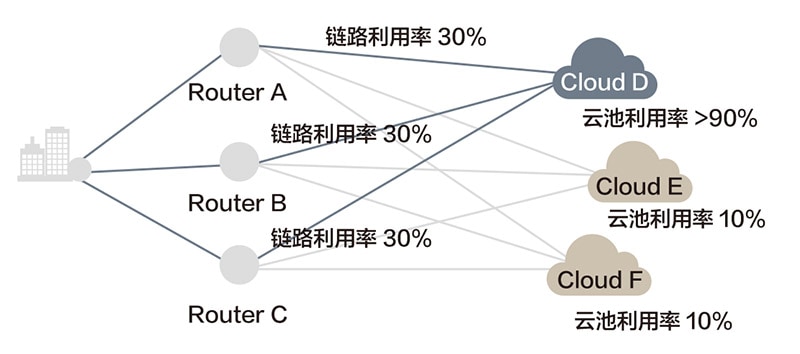
图4 广域网传统的调度模式
为了解决这一问题,华为引入了智能云图Edge-Disjoint KSP算法,该算法融合了网络的时延、带宽、可靠性、可用度等网络因子和云池的算力负载、存储资源、成本等云因子进行云网地图建模,通过多维约束的动态并行计算获得了不同业务的最优路径推荐,按照推荐结果对SRv6报文的路径标签进行了定义和编排,同时将业务数据携带在SRv6报文中,全网路由器可根据业务类型实现最优路径转发,从而实现了云池、网络、业务质量的整体最优。基于云因子与网因子的一体化调度,该算法不仅可根据企业的需求选择最佳云池,还可实现多源到多宿的云网资源平衡,将算力输送效率提升了30%以(图5)。
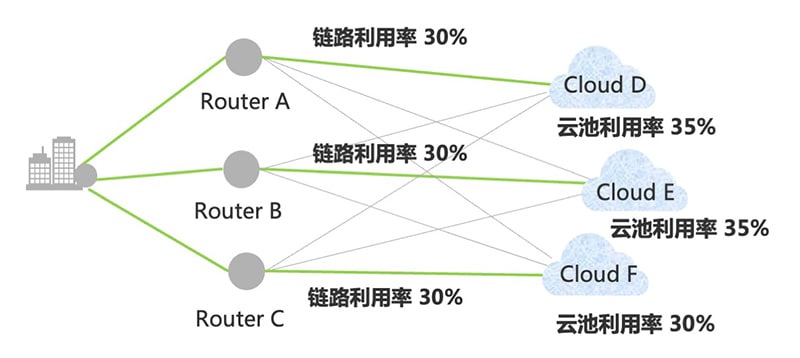
图5 广域网络的云网一体化调度
早在2016年,国家就提出了“建设一体化大数据中心”的指导思想,如今,新型算力网络的概念已经深入人心,华为正在积极参与国家枢纽节点的方案设计与建设,通过IP网络方案的持续创新,推动“东数西算”工程的顺利开展,为数字经济提速注入强劲动力。

 1
1 2
2 3
3 4
4 5
5 6
6



