火热的AI大模型,没有昇思怎么行?
看昇思MindSpore超大规模AI训练推理部署关键技术如何解决计算Scale Up和Scale Out难题。
本站点使用cookies,继续浏览表示您同意我们使用cookies。Cookies和隐私政策

深度学习以TikTok的节奏发展,一轮模型架构创新,接着一轮学习范式创新。自2018年,谷歌发布基于注意力机制的Transformer模型架构以来,近三年时间里,诞生了大量基于Transformer架构的算法。而近期火热的大模型,可以说是Transformer算法架构之上一种学习范式的创新,通过超大规模的模型参数及超大规模的数据,实现了深度学习新的突破。
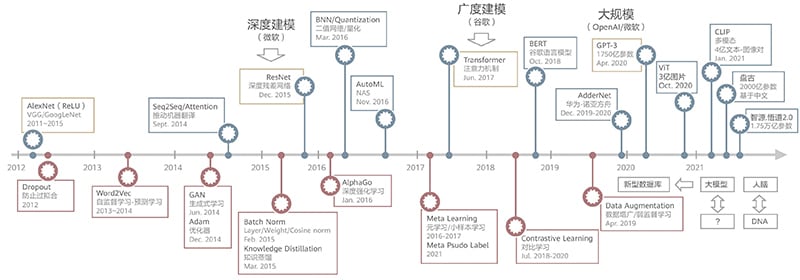
图 深度学习算法TikTok演进节奏
例如,OpenAI发布的GPT-3,在多项NLP任务中超越了人类水平。在两年多的时间里,GPT-3模型规模增长了上千倍,所需算力也是同步增长。业界称这种由“大模型+大数据+大算力”构建起来的新型深度学习范式为超大规模AI。
超大规模AI正成为下一代人工智能的突破口,也是迈向通用人工智能最有潜力的技术方向。产业界和学术界都看到了这种新型范式的潜力,纷纷入局,在OpenAI之后,华为发布了盘古大模型,智源发布了悟道大模型,M6大模型等。
从AI框架计算角度看,大模型可以分成四类:
第一类,稠密Transformer。OpenAI GPT-3、华为云盘古NLP、鹏程.盘古,这些模型规模扩展是全结构扩容。
第二类,稀疏MoE结构Transformer。Google Switch Transformer、智源悟道2.0、阿里M6等,这类模型都是选择一个基础的稠密模型,通过MoE稀疏结构扩展FFN部分来实现模型的扩容。
第三类,高维稀疏特征推荐模型。常用的广告推荐算法,主要依靠高维稀疏特征Embedding实现超大参数。
第四类,超高分辨率图像。如遥感图像处理领域,一张图片可达12GB甚至更大,模型的参数量虽不大,但输入输出和激活量很大。
作为一种新型深度学习范式,超大规模AI为什么能在这两年有所突破?背后的大功臣是算力突破性的发展。大模型大数据的深度学习,对算力的需求可达E级。2020 年,华为与鹏城实验室合作,建成了国内第一个E级算力的人工智能计算中心,为这轮超大规模AI范式的发展准备好了基础软硬件平台。
超大规模AI对AI框架也提出了新的挑战,即如下总结的六堵墙。
内存墙:以鹏程.盘古大模型为例,参数量200B,模型训练过程中需要存储参数、激活、梯度、优化器状态,一个模型的训练就需要占用近4TB的内存。业界主流训练卡,如昇腾910,一张卡的内存是32GB,也就是说需要100多张卡才能跑一个模型。
计算墙:鹏程.盘古200B参数量的大模型,需要3.6E23 FLOPS算力,即使能把昇腾910 256T的理论算力发挥出来,也需要44年才能训练完。
通信墙:大模型并行切分到集群后,模型切片之间会产生大量通信,从而产生通信瓶颈。只有综合考虑参数量、计算量、计算类型、集群网络带宽拓扑等,才能设计出性能较优的并行切分策略。
效率墙:算法的分布式并行开发一直是并行计算领域的一大难题,如何让用户高效编写分布式并行的代码,也是各种AI框架研究的重点和难点;在HPC时代是MPI编程范式,大数据时代是MapReduce编程范式,而超大规模AI时代,我们需要怎样的编程范式?
调优墙:昇腾E级算力集群有4096个节点,在E级算力集群上训练一个千亿参数规模的模型,节点之间的通信关系非常复杂,要保证计算的正确性、性能和可用性,手动调试难以全面兼顾,需要一个自动化及可视化的集群分析工具。
部署墙:超大规模AI从训练到部署需要一个转换,同样以鹏程.盘古大模型为例,训练时用了千卡,云上推理部署需要64卡,中间需要把千卡的训练无缝地转接到64卡的推理。同时,为了进一步降低推理成本,需要把模型进行压缩,实现一张卡就能运行。
昇思MindSpore通过多维度自动混合并行,解决了模型及集群的Scale Out问题,支持超大规模模型切分到大集群高效训练,并实现优质的计算通信比,进而提升算力的利用率。方案创新性地在AI编译器中实现了多维度混合并行,支持数据并行、模型并行、流水并行、优化器并行、子图并行等多维度的AI并行计算技术。用户可以根据模型的特征,选择不同的并行策略组合,实现优质的计算通信比,提高训练性能。
通过全局的内存管理及计算调度,昇思MindSpore能够提升单卡的Scale Up能力,包括图算融合、CPU/NPU异构并行,以及实现CPU内存、NPU内存和NVMe三层存储的统一管理。同时,昇思MindSpore在昇腾硬件平台上与CANN深度结合,通过深度协同优化的高性能算子库,充分释放硬件的澎湃算力。
对于Transformer类的大模型,例如鹏程.盘古大模型的训练,采用了数据并行、模型并行、流水并行、优化器并行、重计算等技术叠加;而中科院紫东.太初三模态大模型是一种MoE架构的稀疏模型,则采用了数据并行、模型并行、MoE并行、优化器并行、重计算等技术叠加。
在推荐领域,模型的特征是Embedding层非常大,具备高维稀疏的特征,所以往往会采用Embedding模型并行,以及Embedding之后DNN数据并行的训练策略。在大规模推荐场景,Embedding能达到10TB级别,所以除了采用模型并行以外,昇思MindSpore还会把Embedding Offload到CPU内存,从而扩大单卡可运行的模型容量。超高分辨率图像处理领域的遥感模型武汉.LuojiaNet,则是采用了数据并行和模型并行叠加的训练方式。
总体来说,不同的模型架构和数据规模,在不同的集群之下,需要采用不同的并行策略,才能实现最优的计算效率。这也是昇思MindSpore的差异化能力,通过在编译阶段实现各种并行模式,并行支持多种并行模式自由组合,支持任意类型的模型结构。而目前业界标杆英伟达Megatron则是针对稠密Transformer模型定制,只能支持稠密Transformer模型的分布式并行。
昇思MindSpore通过三层AI分布式编程范式,解决了分布式并行程序的开发效率问题。
最底层的编程范式,昇思称之为手动并行,是一种类HPC领域的MPI编程范式,通过提供类MPI集合通信原语,用户可以用编码的方式,手动把模型切分到集群进行并行计算。这种类HPC的编程范式,用户在开发时需要通过编码来解决算子切分、图切分、集群调度等问题,开发门槛最高,但最灵活,可以实现任意的并行模式。
在手动并行基础上,昇思MindSpore通过图编译的方式,实现了半自动并行,把并行逻辑和算法逻辑解耦,用户还是按单卡串行的方式编写算法代码,当需要进行分布式并行时,只需加上一些并行的配置,这样可以极大提升用户的开发效率。在半自动并行之上,昇思MindSpore还提供了一种全自动的并行方式,用户只需编写单机串行代码,即可全自动实现模型的切分。
全自动并行一直是分布式并行计算领域的研究难题,是分布式并行计算皇冠上的明珠,始终没有得到很好的解决。MindSpore结合AI领域计算的特点,目前已实现了部分AI计算的全自动并行。
模型训练出来后,需要上线部署推理服务,昇思MindSpore实现了从分布式训练到分布式推理的自动转换,以及大模型快速上线部署。鹏程.盘古是最大的稠密形式的中文预训练语言模型,拥有200B参数,训练时使用了2048卡,推理时需要64卡。并行训练模式采用了数据并行、模型并行、优化器并行、流水并行、重计算等,而推理时只需采用模型并行和流水并行。
基于MindSpore的分布式并行能力,鹏程.盘古可自动从分布式训练模式转换成分布式推理模式,并实现服务化封装,可以对外提供RESTful接口,支持快速上线大模型服务。
在超大规模AI快速发展期间,昇思MindSpore支持了鹏程.盘古大模型、华为云盘古NLP大模型、中科院紫东.太初三模态大模型、鹏程.神农生物信息研究平台、武汉.LuojiaNet智能遥感解译框架等的开发训练。
展望未来,华为将会支持更多客户研发更多种类的大模型,繁荣昇腾全栈支持的超大规模AI生态。

 1
1 2
2 3
3 4
4 5
5 6
6



